yes I will write a simple sphere shade that draw a ball from a quad so that I can check the sph physics, the point draw is not really correct because the points are 4 pixels size independent of the distance to the camera. but I wrote it like that intentionally because that function is a debug function to see contacts. Not doing it like that, and the contact far away because invisible because of the z buffer fight.
anyway, I now try to complete the iso surface and I found the first problem.
the function was very fast as long as there are many interion points that get rejected.
but as soon as the particles stat to move, now the surface goes from few thousand triangles to hundreds of thousands. that makes sense, for example a 40 x 40 x 40 point is 64 k points,
if the positions are close together, the mesh only covers the surface area, but of the point are all fart apart, now each point made 8 triangles, and that 64k * 8 = 0.5 million triangles.
that quite a hefty amount of data for a single core.
so I guess that form here, the best hope, is make the background thread multicore, and also OpenCL,
I realize that it is not reasonably to expect that real time performance for in a single core for data set approaching a million elements.
that seem like a real big problem, that can Onel be solve by adding more threads.
however, I took a look and the thing to my surprise that part that takes the most time is not making the surface but converting the vertex list to a triangle list.
I made a test that randomize the position so that it generates one of the worst-case mesh like the one below
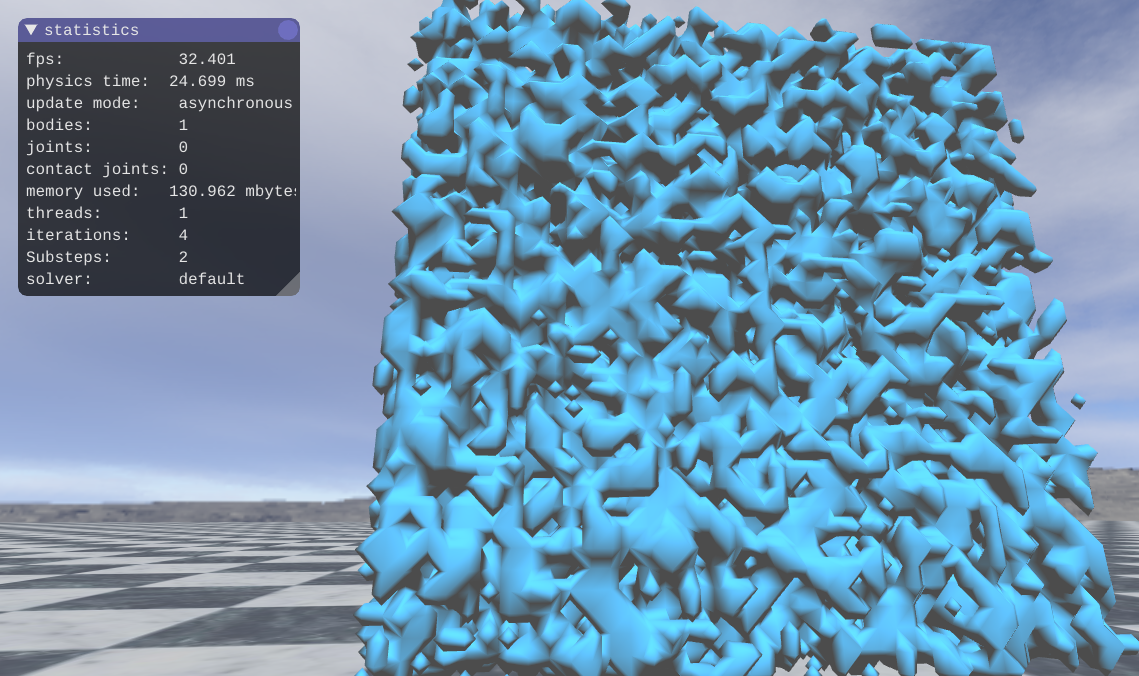
- suspension.png (766.76 KiB) Viewed 4903 times
as you can, see it takes for 24 to 26 ms just to make that mesh. the triangles list cone at about 600 k vertices.
so OI modify the iso surface so that is generate just the vertex list only, then I added a function that is called after the surface is produce, it makes the index list, and this is the result.
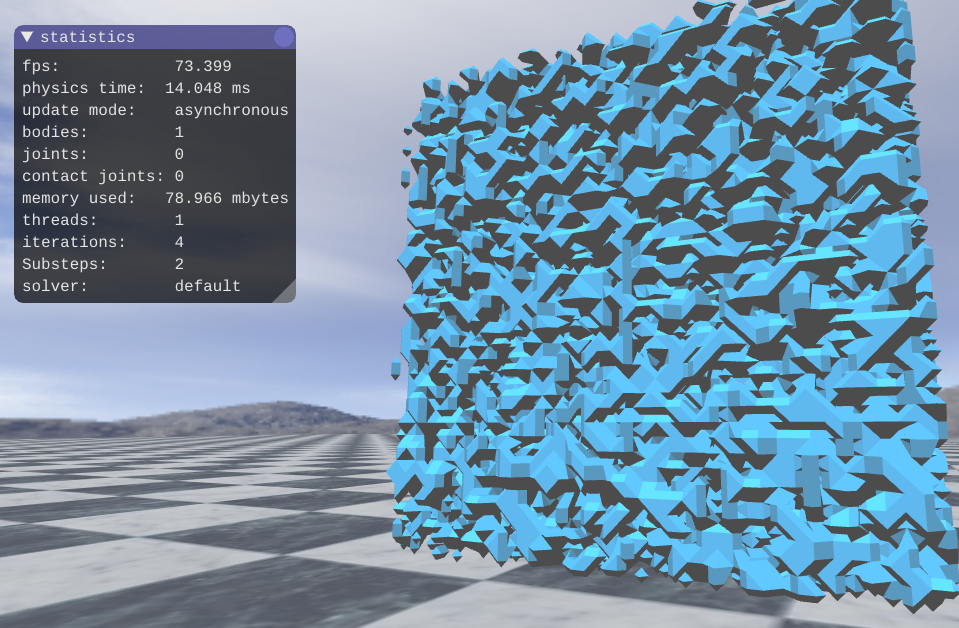
- Untitled.png (387.37 KiB) Viewed 4903 times
as you can see in 10 ms faster, but it is flat shaded.
The good news, is that generation the vertex list is still under 16 ms, which means that we can be delegated it to a background thread, and if we make the background thread to have a thread pool, then that time can be cut to probable 7 to nine ms, which is on target
anyway, before I go back to the simulation, I will make the background thread use a thread pool, and parallelize the iso surface generator.

