ok I now made the change that the doc talk about here
https://developer.nvidia.com/blog/how-o ... s-cuda-cc/I did not get the result they claim but I do it anyway.
I do regret that the code become more complex. since we nwo have double buffer in cpu and double buffer in gpu.
bassically the sequence now is.
in GPU, there are two streams the compute stream and the memory copy stream.
at the beginning of each frame there is a frame synchronize. (btw that was the messing part that was showing the weird behaviors in the profile when many frame were accumulated in a way that did no make since. Now with device sync at the beginning of each frame the divide are more predictable.
It does not fixes the mysterious silences gaps, but it is better.
anyway the sequnece in GPU is not this
frame begin:
-device Sync
-memcpyasync oddFrame from GPU to CPU host buffer using the memcpy stream.
-excute all scene and solver kernels. (scene, collsion, solver, etc) using the solver Stream
-Copy in gpu the transforms to the even Frames, also using solver Stream
in cpu:
copy the transform form CPY od frame to the rigid bodies.
end Frame:
swap GPU buffer,
increment Odd/Even counter.
these are the result. Old system.

- Untitled.png (35.26 KiB) Viewed 3445 times
as you can see there is only one stream and memcpy and compute shader are all executed sequentially.
here is the newer method.
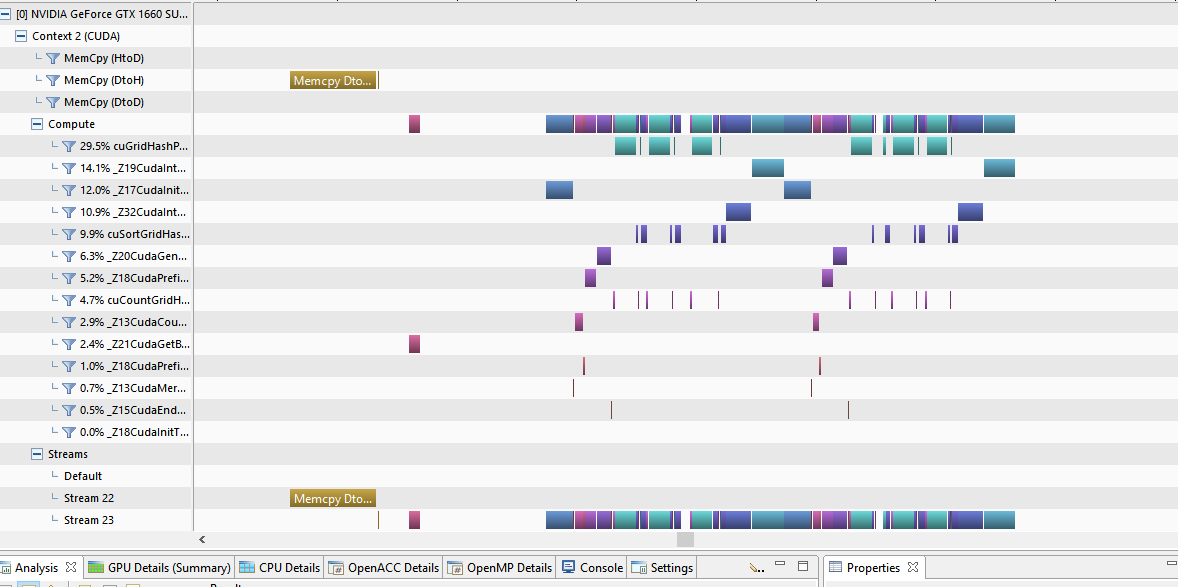
- suspension.png (41.84 KiB) Viewed 3445 times
nwo there are tow stream, and according to teh Doc, these serius of GPU have two a dma chanel that is indepemnde of the Compute, so the can do simultanuslly
1 memcpy, for CPU to GPU, 1 memcpy form GPU to CPU and comuputed kernels.
one memcpy can be GPU to GPU
but the picture below show the memcpy in separate stream by it is not concurrent.
so either I am missing something, ot this GPU does not support it.
but I leave it anyway, because this is how we can exploit the advance features of the GPU.
I will debug it and committed it later, then people interested can check it out if it works.
now before moving on they one last optimization I nee to apply and them we can move to Generate colliding pairs.

